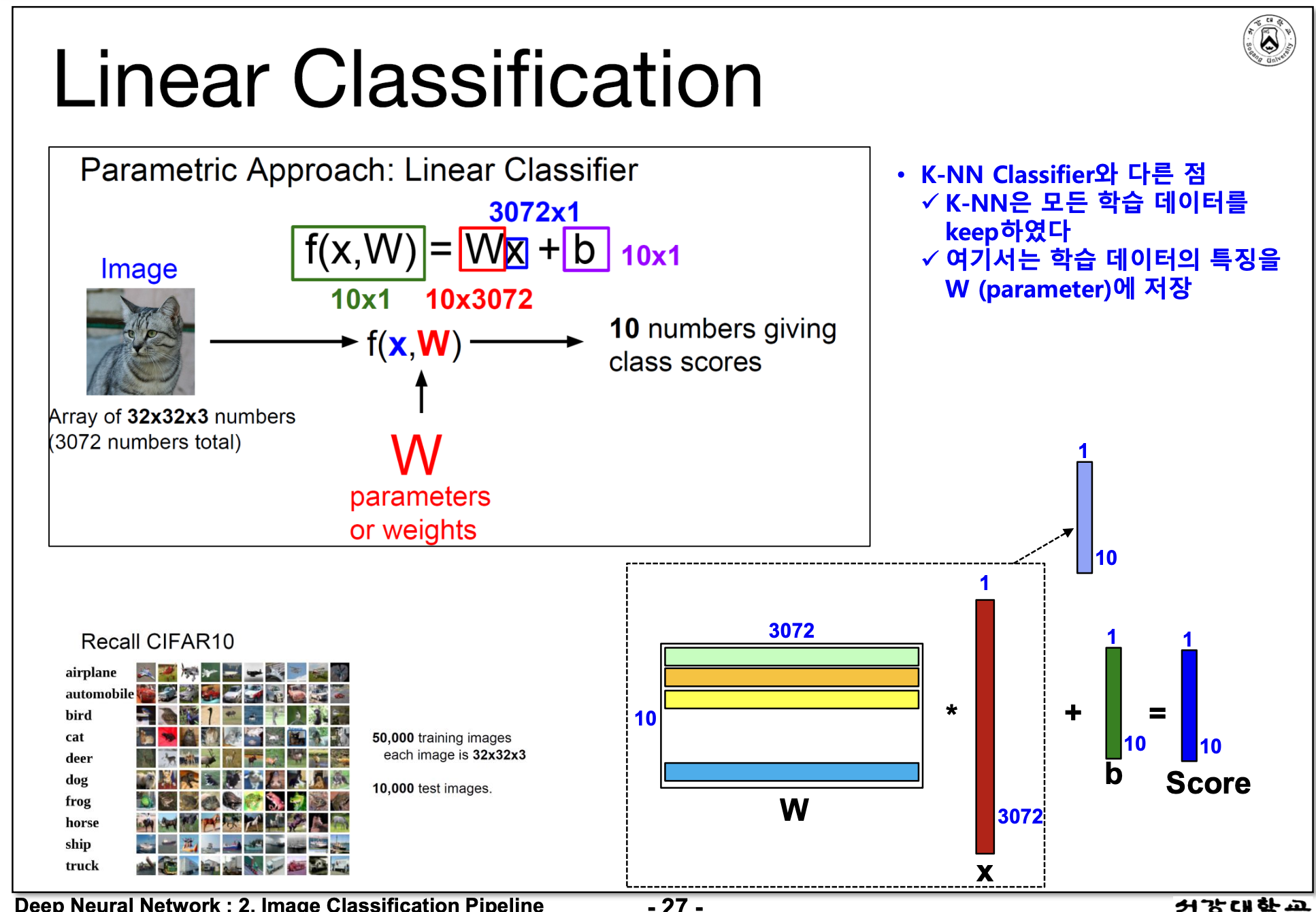
- Nearsest Neighbor -> K-Nearest Neighbor > Linear Classifier (대푯값을 이용하자) -> 그렇다면 W가중치는?
- data-driven approach! 기계학습은 데이터 기반으로 '기계가' 룰을 찾게하는 것
- data space 데이터 공간
- CIFAR dataset의 차원 : 32 x 32 x 3 = 3072 차원
- Nearsest Neighbor란? distance가 가장 짧은 것을 학습해나가는 것 (근데 성능이 좋지 않음)
- 거리를 측정하는 방법에는 유클리드, 맨하탄 방법, 코사인 similarity 있음
- 단점 : Nearest는 테스트할 때 시간이 많이 소요됨


- K-neareast
- Nearest Neighbor를 noise를 보완할 수 있음

- 차원의 저주란?
- 데이터의 차원이 높아질수록 필요한 데이터의 개수가 기하급수적으로 늘어난다. 근데 우리가 갖고 있는 데이터는 그만큼 갖고 있지 않고 있기때문에 기계학습 성능 떨어진다.
- 따라서 기계학습에서는 고차원 데이터를 저차원 데이터로 변환해서 학습한다. (PCA or Feature Extraction)
- 고차원 -> 저차원으로 축소할 때는 manifold Hypothesis를 가정하고 있다.

- 차원축소 feature extraction/PCA : 고차원 -> 저차원 데이터로 줄인다음에 기계학습 (manifold를 가정)
- Manifold 가정 : 이 세상에 있는 모든 데이터들은 고차원이라고 할지라도 실제적으로 저차원 공간에 분포되어있다. 즉, 우리가 다루는 데이터가 수백, 수천 개의 차원을 가지더라도, 이 데이터들이 실질적으로는 더 낮은 차원의 구조 위에 놓여 있다는 가정
- inner product : 비슷한 클래스면 score가 가장 크다
- x는 3072차원의 데이터, W는 class 10개 x 3072, Linear Classifiaction
- 입력에 대해 1차원 함수 : Nearest할때 100만번해야했지만, Linear는 대표이미지로 10번만 하면된다.
'대학원' 카테고리의 다른 글
| 서강대학교 AI/SW대학원 2025년 전기 신입학 일정 (0) | 2024.11.03 |
|---|---|
| 20241010_연차쓰고 pc방에서 대학원 접수하기 (3) | 2024.10.10 |

