Attention is All You Need 논문 리뷰 중 내용을 이해하면서 정리해나가는 글.
아키텍쳐 구조를 이해하는 것과, 또 이를 구현하는 일은 별개의 영역이지만 계속해서 듣다보면 이해가 된다.
Transformer 등장 배경
- RNN과 LSTM의 한계
- 순차적인 처리 방식으로 인해 병렬 연산이 어렵고, 학습 속도가 느림.
- 긴 시퀀스를 학습할 때 기울기 소실(vanishing gradient) 문제 발생.
- 장기 의존성(long-term dependency) 학습이 어려움.
- Seq2Seq 한계
- 고정된 크기의 context vector 사용하기 때문에 정보 손실과 성능 한계가 있었음
- CNN의 한계
- CNN은 이미지 처리에 강하지만, NLP와 같은 시퀀스 데이터에서 문맥을 포착하는 데 한계가 있음.
- 커널 크기로 인해 멀리 떨어진 단어 간 관계를 학습하는 데 제한이 있음.
- Self-Attention 기반의 혁신
- 트랜스포머는 Self-Attention 메커니즘을 활용하여 모든 입력 토큰이 서로를 참조할 수 있도록 설계됨.
- 이를 통해 장기 의존성을 효율적으로 학습할 수 있으며, 병렬 연산이 가능하여 학습 속도가 획기적으로 향상됨.
- --> Transformer는 RNN 기반을 사용하지 않고, 오직 Attention 기반을 활용한 Transformer를 제안

Transformer 구조
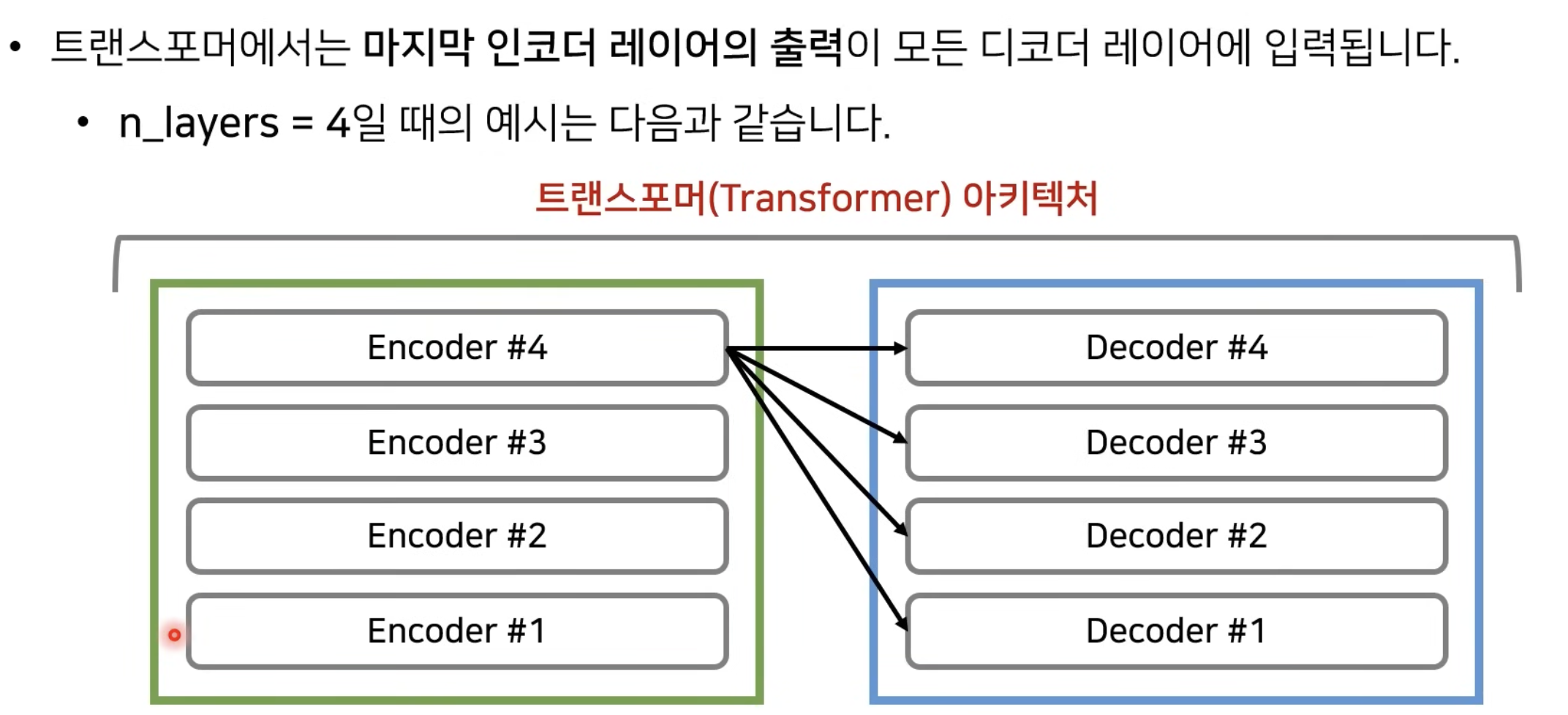
- 트랜스포머는 크게 Encoder와 Decoder 두 가지 구조로 구성되어 있다.
- 인코더는 쉽게말해 컴퓨터가 입력받은 자연어를 인식/이해할 수 있도록 숫자로 변환하는 과정을 말한다.
- 예를들어, 영어 문장 "I love AI''를 한글로 번역할 때 해당 문장을 모델의 입력값으로 받으면
- 인코더는 각 단어를 벡터로 변환하고 → ["I", "love", "AI"] → [벡터1, 벡터2, 벡터3]
- 트랜스포머 인코더가 입력을 처리 → [벡터1, 벡터2, 벡터3]을 고차원 특징으로 변환한다.
- 디코더는 쉽게말해 인코더가 생성한 맥락 정보(context)를 받아 토큰으로 최종 값을 출력하는 것을 말한다.
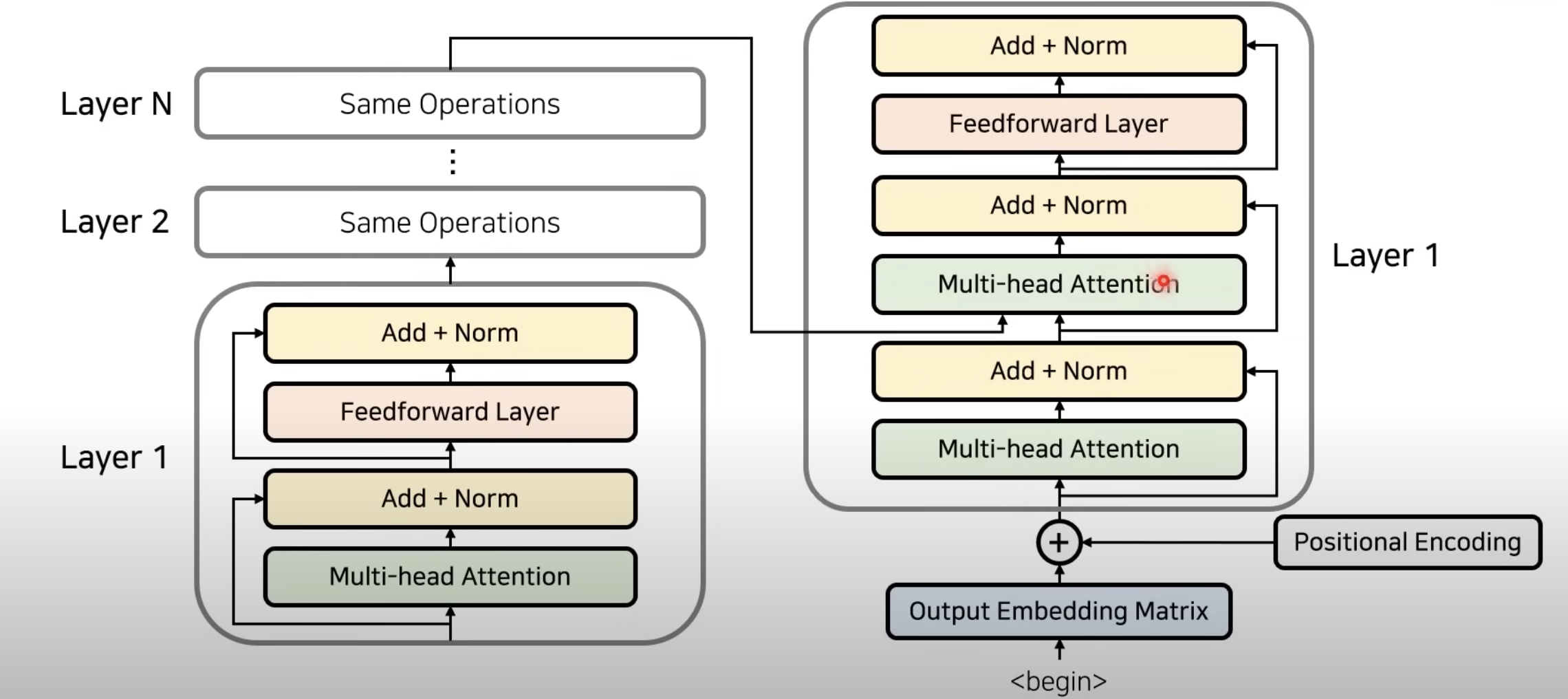
1. Encoder 인코더
1.1 포지셔닝 인코딩 : 단어의 순서 정보를 학습
- 트랜스포머는 RNN과 달리 순차적인 정보 처리를 하지 않음 → 토큰 간의 순서를 구별할 방법이 필요.
- 이를 해결하기 위해 포지셔널 인코딩을 사용하여 각 입력 토큰의 위치 정보를 추가.
2. 멀티헤드 어텐션 : 단어간 관계를 병렬적으로 학습
- Self-Attention: 입력 토큰들이 서로를 참조하여 문맥(context)을 파악.
- Multi-Head: 여러 개의 어텐션을 병렬적으로 수행하여 다양한 관점에서 관계를 학습
- Encoder 내 Self-Attention
3. Add + Norm
- 각 서브레이어(멀티헤드 어텐션, FFN) 뒤에는 잔차 연결 (Residual Connection)과 Layer Normalization을 수행하여 안정적인 학습을 유도한다.
4. FeedForward
- 어텐션 이후 각 위치의 토큰을 개별적으로 변환하는 두 개의 완전연결층(FC)으로 구성된 네트워크
2. Decoder 디코더
- 한개의 Decoder Layer에서는 두개의 Decoder Attention을 수행
- (Self Attention) 첫번째 Self-Attention은 Encoder Attention과 동일하게 각각의 단어들이 서로에게 어떠한 가중치를 가지는지 구하도록 만들어서 출력되고 있는 문장에 대한 표현을 학습하고
- (Encoder-Decoder Attention)두번째 Attention은 Encoder의 Attention을 입력으로 받아, 출력 단어가 source 단어와 연관성이 있는지를 보는 것
Reference
- https://youtu.be/KT58deB6oPQ?si=fsHjHITQzl8nvZYV
- https://youtu.be/AA621UofTUA?si=h8FGRGiutmN2sVfJ
- https://youtu.be/x_8cp4Vdnak?si=kkmcm7wwroszSuVd
'AI > AI 이론' 카테고리의 다른 글
| 250408_Batch Normalization과 Layer Normalization의 차이 (0) | 2025.04.08 |
|---|---|
| 250311_텐서플로우기초 (0) | 2025.03.11 |
| 250310_딥러닝기초_01 (0) | 2025.03.10 |
| [머신러닝기초] Cross Entropy 크로스 엔트로피 (1) | 2024.12.02 |


