https://youtu.be/h9T9HlVvsDo?si=HXl0_8eMJ4kJDRp_
이 영상은 순환 신경망(RNN)의 개념과 동작 원리를 자세히 설명합니다. 일반 신경망과 RNN의 구조적 차이점, 즉 RNN이 어떻게 과거의 데이터를 기억하고 현재의 데이터와 연결하여 의미를 파악하는지를 다룹니다. 또한 문장 내에서 단어의 의미는 그 위치에 따라 결정되며, 이러한 순서 있는 데이터 처리의 중요성을 강조합니다. 따라서 이 영상을 통해 RNN의 특성과 데이터 처리 방식을 이해할 수 있습니다.
핵심주제
RNN은 순환 구조를 통해 시퀀스 데이터를 효과적으로 처리한다.
- RNN은 입력, 은닉, 출력 층으로 구성되지만, 일반 신경망과는 달리 과거 데이터를 기억하는 기능을 갖추고 있다.
- 이 구조 덕분에 RNN은 시간적 순서가 중요한 데이터, 즉 문장이나 음성과 같은 연속 데이터를 잘 처리할 수 있다.
- 따라서 RNN은 순서 있는 데이터를 다루는 데 강점을 가진 모델로 알려져 있다.
RNN은 문장에서 단어 위치에 따라 의미를 이해하는 능력을 갖춘다.
- RNN은 각 단어의 위치를 인식하여 문장 전체의 의미를 판단하는 데 중요한 역할을 한다.
- 예를 들어, 'I walk at Google'이라는 문장에서 각 단어의 기능을 제대로 이해하기 위해서는 순서가 필수적이다.
- 이러한 점에서 RNN은 단어의 순서를 고려하여 맥락을 이해하는 데 도움을 준다.
RNN의 동작 원리는 과거 각각의 데이터와 현재 데이터를 연결하여 이해하는 것이다.
- RNN은 이전 데이터와 현재 데이터의 관계를 분석하여 각 단어의 확률을 계산한다.
- 예를 들어, 대명사 '아이' 뒤에 오는 '워크'라는 단어는 그 문맥을 파악하여 동사일 확률이 높아진다.
- 이와 같은 연결을 통해 RNN은 문장 내의 데이터 간의 관계를 잘 처리할 수 있다.
시간적인 순서는 RNN에서 중요한 요소이다.
- RNN은 순서 있는 데이터를 처리할 때 시간의 흐름을 고려하여 데이터를 입력받는다.
- 이러한 시간적 연관성을 통해 RNN은 이전 정보를 기억하고 새로운 정보를 처리하여 보다 나은 이해를 이루게 된다.
- 결국 RNN의 이러한 특성은 시계열 데이터 분석에 매우 적합하다.
타임라인
1. 🧠 RNN 아키텍처의 특징과 일반 신경망과의 비교

- 일반 신경망은 입력 층, 은닉 층, 출력 층으로 구성되어 데이터를 처리한다.
- 일반 신경망은 피드 포워드를 통해 손실 값을 계산하고, 최적화하여 가중치와 바이어스를 업데이트한다.
- RNN도 입력 층, 은닉 층, 출력 층으로 구성되는 점에서 일반 신경망과 유사하다.
- 그러나 RNN의 은닉 층은 일반 신경망과 두 가지 부분에서 크게 다르다.
- 이 차이로 인해 RNN은 과거의 데이터를 기억하면서 현재의 데이터를 처리할 수 있다.
2. ANN 대비 RNN의 두 가지 중요한 차이점
- 첫 번째로, 일반 신경망의 은닉 층은 활성화 함수를 사용하여 출력 값을 계산하고 출력 층으로 전달하지만, RNN은 탄젠트 하이퍼볼릭(tanh)를 사용하여 출력 값을 계산한다.
- 두 번째로, RNN의 가장 큰 특징인 순환 구조는 은닉 층 내에 존재하며, 일반 신경망에서는 계산된 값이 바로 출력 층으로 전달되지만, RNN에서는 출력 값이 순환되어 다시 입력 층으로 들어간다.
- 이러한 차이로 인해 RNN은 순서 있는 데이터를 처리하는 데 강점을 가진 신경망으로 알려져 있으며, 이 순서가 의미하는 바와 RNN이 데이터를 어떻게 인식하고 처리하는지에 대한 설명은 다음 장에서 다룰 예정이다.
3. 문장의 단어 위치에 따른 의미 변화
- '아이워크 앱 굴 나는 구글의 근무하고 있어'에서 '워크'는 동사이고 '구글'은 명사임을 알 수 있으며, 반대로 '아이구 그래도 학 나는 회사에서 구글링'에서는 '구글'이 동사이고 '워크'가 명사로 쓰였다.
- 따라서 문장 내에서 단어의 위치에 따라 의미가 달라진다는 점이 중요하다.
- 이처럼 연속적인 데이터, 즉 문장이나 음성의 순서는 그 의미를 명확히 정의하는 데 필수적이다.
- 예를 들어 'I walk at Google'에서 '워크'와 '구글'의 역할을 이해하려면 그 앞에 있는 대명사 'I'와 전치사 'at'를 인식해야 한다.
- 오늘 학습할 RNN은 이전 데이터를 기억하고 새로운 데이터와 연결하여 의미를 이해하는 구조를 가지고 있다.
4. ️🤖RNN의 동작 원리와 출력 분류 이해하기
- 'I work at Google' 문장을 통해 RNN의 동작 방식과 의미 파악을 설명합니다.
- 은닉 layer는 순환 구조를 가지며, 입력 데이터 '아이'가 들어오면 탄젠트 하이퍼볼릭 계산을 진행하고 순환 구조를 통해 기억됩니다.
- 출력 층은 소프트맥스를 사용해 확률로 결과를 나타내며, 현재 '아이'의 출력 값은 대명사 0.97, 명사 0.03 등으로 분류됩니다.
- 따라서 '아이'는 대명사일 확률이 가장 높아 대명사로 판단됩니다.
- '워크' 데이터 또한 은닉 층으로 들어가며, 이전 데이터 '아이'가 기억되어 있다는 점에서 RNN의 효과를 보여줍니다.
5. 데이터 연결을 통한 동사 판단 과정
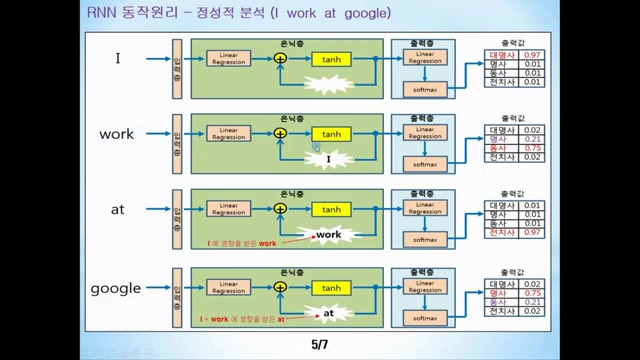
- 현재 데이터 '워크'와 이전의 '아이' 데이터를 연결해 은닉층의 계산 값을 마련한 후, 이 계산 값을 출력층으로 전달하며 '아이'의 영향을 받은 '워크'가 기억되는 과정을 알 수 있다.
- 출력층에서는 '아이'의 영향을 받은 입력 데이터가 동사인지 명사인지 판단하며, 아이가 대명사로 쓰였기에 대명사 뒤에는 동사가 올 확률이 높다고 분석한다.
- 이로 인해 워크가 동사일 확률을 75%로 평가하게 된다.
- 세 번째 입력 데이터는 비전 데이터로 기억되고 있는 워크와 연결되어 최종 출력층에서는 전치사로 판단하게 된다.
- 입력으로 들어올 때 특히 대명사 '아이'의 영향을 받은 워크를 반드시 기억해야 한다.
6. ️🧠RNN의 동작 원리와 과거 데이터 연결
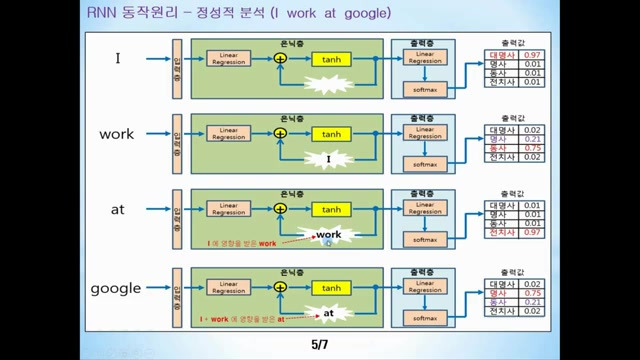
- 최종 출력층에서 구글이라는 입력 데이터를 통해 명사로 판단하는 과정을 설명한다.
- 입력된 데이터인 '구글'은 문장의 끝에 위치하고, 이전의 대명사, 동사, 전치사는 명사일 확률을 높인다고 이해된다.
- RNN은 순환 구조를 활용하여 과거 데이터와 현재 데이터를 연결해 순서가 있는 데이터 해석을 가능하게 한다.
- 이러한 순환 구조는 시간 개념을 포함해 과거의 데이터를 기억하고, 새로운 데이터와 연결되는 방식으로 표현된다.
- 예를 들어 '아이 워크 앳 구글' 데이터를 입력할 경우, 입력되는 각 단어 사이에는 시간의 차이가 있음을 알 수 있다.
7. 시간적 순서를 가진 데이터의 개념 설명
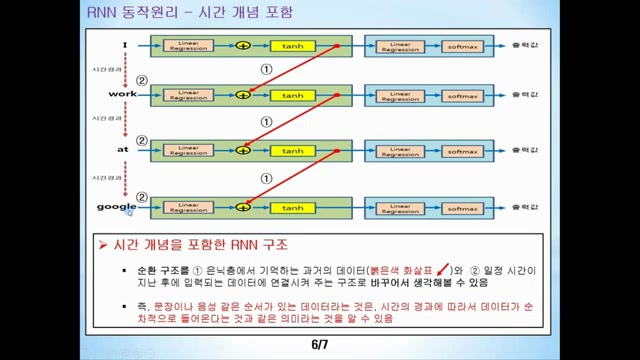
- 문장이나 음성과 같은 순서가 있는 데이터는 시간 경과에 따라 순차적으로 입력된다는 의미입니다.
- 지금까지 기본 개념, 구조, 동작 원리 등을 검토하였고, 다음 시간에는 심플 RNN의 구조와 API를 다루면서 이러한 API를 이용한 시계열 데이터의 예제를 선보일 예정입니다.
'deeplearning > tensorflow(keras)' 카테고리의 다른 글
| 텐서플로우 - ECG 심전도 이상탐지 LSTM by keras (0) | 2024.09.19 |
|---|---|
| 텐서플로우 - LSTM 활용한 삼성전자 주가 예측 (2) | 2024.09.19 |
| 텐서플로우 - CNN CIFAR 10 Example2 by Keras (data augmentation) (1) | 2024.09.16 |
| 텐서플로우 - 이미지 데이터 증강 Image Data Augmentation (0) | 2024.09.16 |
| 텐서플로우 - CNN CIFAR 10 by Keras (0) | 2024.09.15 |


